Abstract
We present a new open-vocabulary detection framework. Our framework uses both image-level labels and detailed detection annotations when available. Our framework proceeds in three steps. We first train a language-conditioned object detector on fully-supervised detection data. This detector gets to see the presence or absence of ground truth classes during training, and conditions prediction on the set of present classes. We use this detector to pseudo-label images with image-level labels. Our detector provides much more accurate pseudo-labels than prior approaches with its conditioning mechanism. Finally, we train an unconditioned open-vocabulary detector on the pseudo-annotated images.
The resulting detector, named DECOLA, shows strong zero-shot performance in open-vocabulary LVIS as well as direct zero-shot transfer benchmarks on LVIS, COCO, Object365, and OpenImages. DECOLA outperforms the prior arts by 17.1 APrare and 9.4 mAP on zero-shot LVIS benchmark. DECOLA achieves state-of-the-art results in various model sizes, architectures, and datasets by only training on open-sourced data and academic-scale computing.
Overview
DECOLA allows users to prompt its detection with a set of class names in language. It adapts its inner-workings to focus solely on the given prompts. This enables DECOLA to learn from a large amount of image-level data through self-training.
Language-conditioned Detecton Transformer
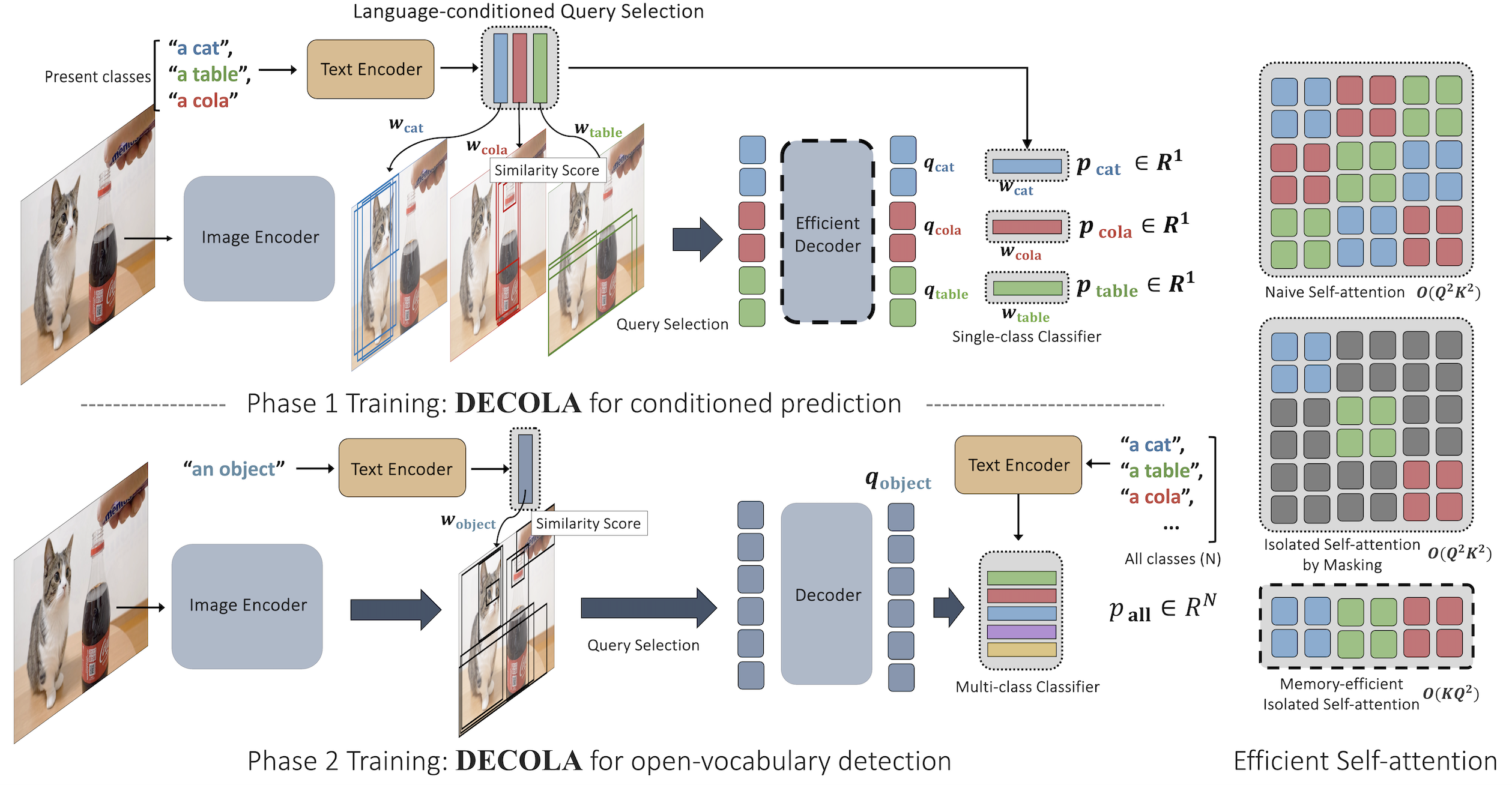
DECOLA is a language-conditioned detection transformer that can be prompted with a set of class names in language. We train DECOLA in two phases:
Phase 1 training aligns input text with object features of image encoder. Specifically, we define the objectness score as similarity between object and text features. Each text prompt proceeds with equal number of object proposals and initialize n language-conditioned object queries. This makes the detector adapt to given text at run-time, highly suitable for pseudo-labeling.
Phase 2 utilizes DECOLA after Phase 1 to generate pseudo-labels for large-scale image-level data. We train DECOLA with the pseudo-labels for unconditioned, open-vocabulary detection by conditioning the proposals with ``an object.'' This allows DECOLA to detect everything.
Evaluating DECOLA
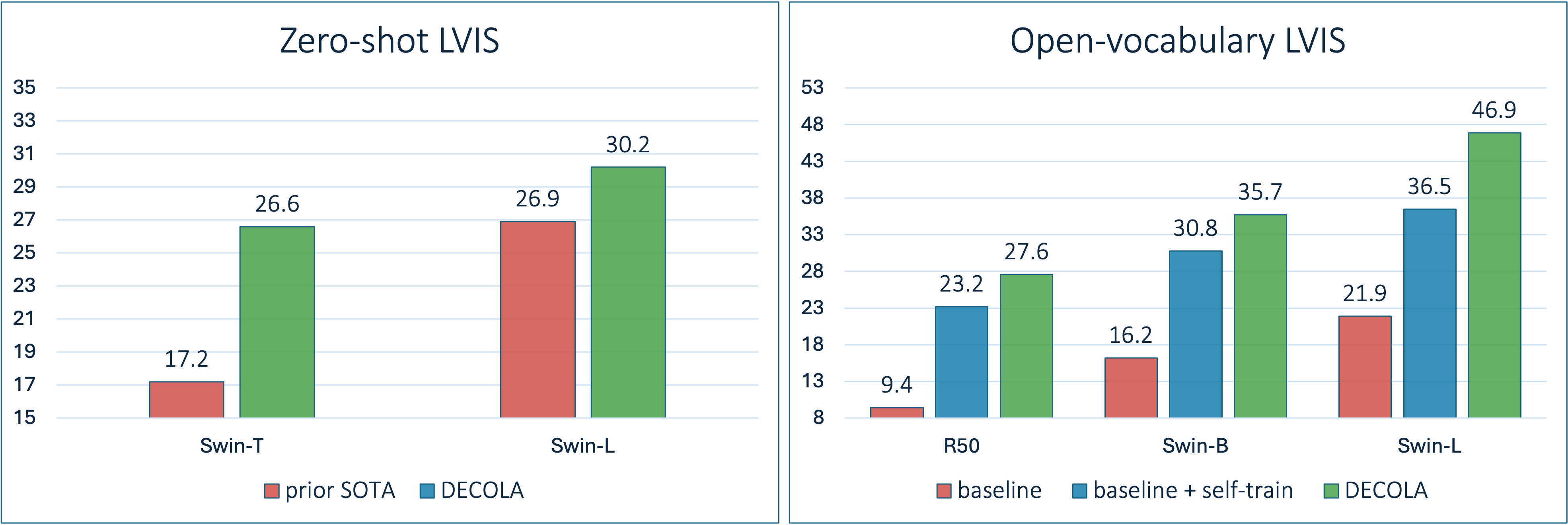
We evaluate DECOLA on zero-shot and open-vocabulary LVIS benchmarks. In zero-shot LVIs, models have no access to target images or vocabulary during training. In open-vocabulary LVIS, models have access to a subset of classes (base classes) and the target vocabulary during training.
Example Pseudo Labels
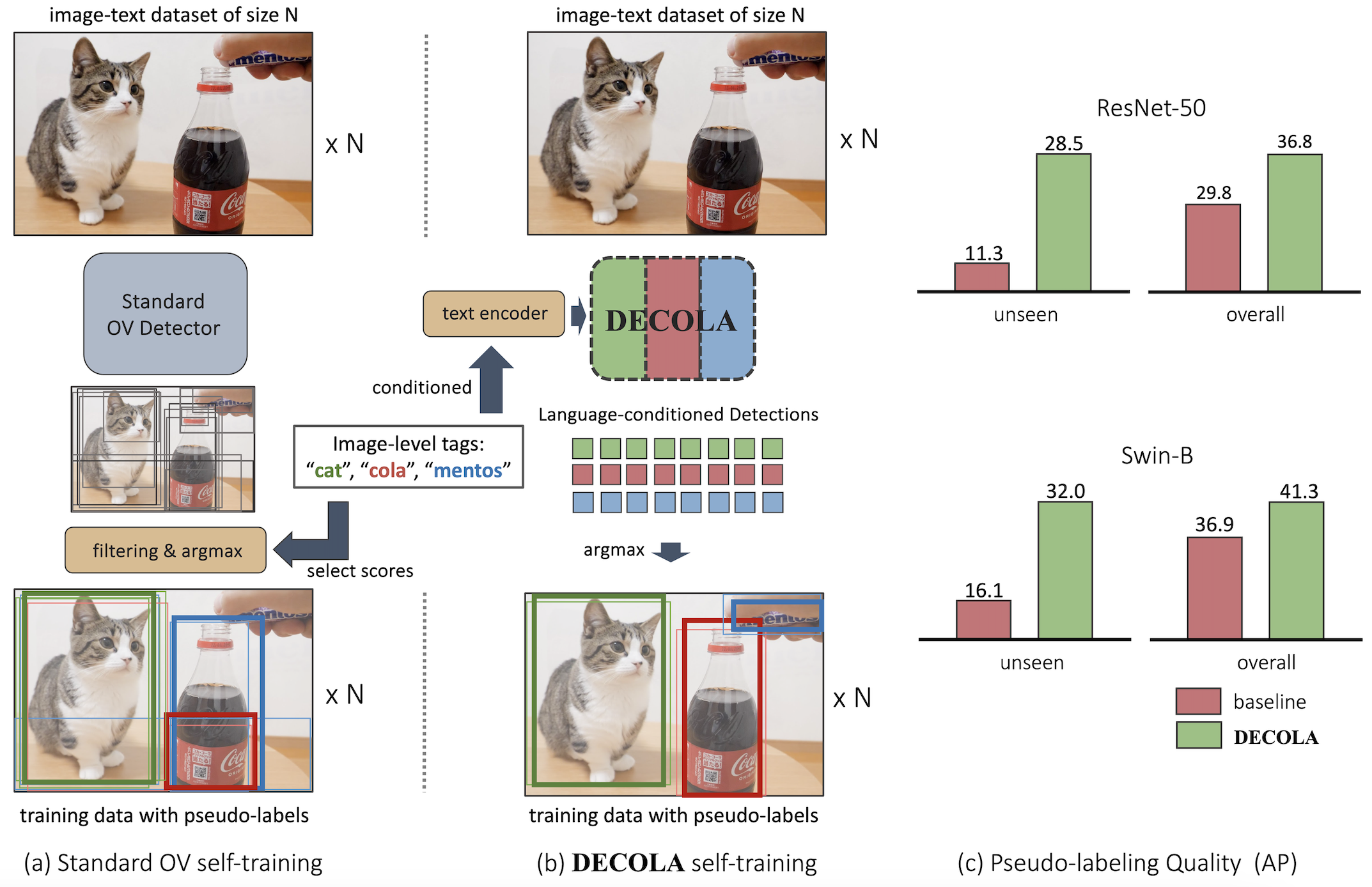
We compare example pseudo-labels of DECOLA (Phase 1) and a baseline. Both models use same architecture and data, and have never seen the images nor trained on the prompted classes. Green boxes are generated by DECOLA and red boxes are generated by the baseline. DECOLA provides much more accurate pseudo-labels than the baseline.

Analyzing DECOLA
We analyze the performance of DECOLA in pseudo-labeling.
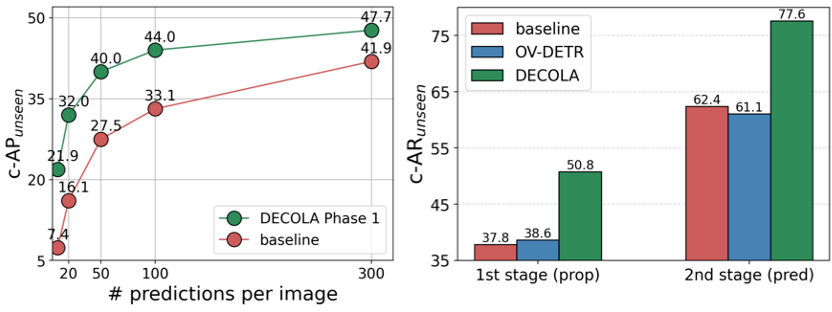
Left, we compare DECOLA with a baseline in how well they can predict completely unseen object categories. We plot the AP against the number of total predictions per-image. Low-shot AP is useful for assessing the quality of pseudo-labels; unlike detection, there are many image-level data to predict but one false-positive can be detrimental during training. In other words, false positive is more crucial than false negative hence we care few most confident boxes.
Right, we compare the average recall of DECOLA and the baseline on unseen classes. We plot the recall of first and second stage of the detector when conditioned to the present classes. Since DECOLA dedicate equal number of proposals to each of the prompted classes, it enjoys high recall even on unseen classes. This is the critical reason why DECOLA can provide accurate pseudo-labels.
BibTeX
@article{cho2023language,
title = {Language-conditioned Detection Transformer},
author = {Cho, Jang Hyun and Kr{\"a}henb{\"u}hl, Philipp},
journal = {arXiv preprint arXiv:2311.17902},
year={2023}
}