Visual CoT Prompting
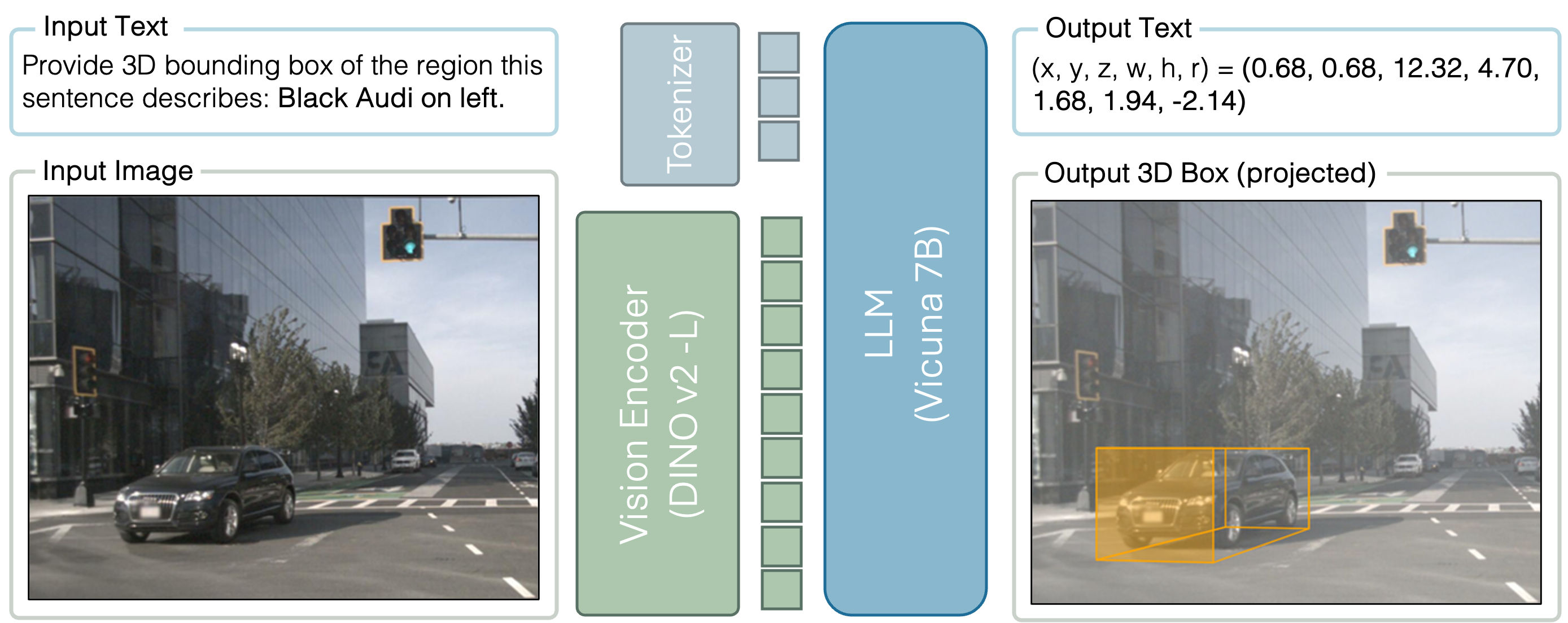
Just like LLM, Cube-LLM improves its prediction by chain-of-thought prompting (CoT), connecting similar reasoning steps together from 2D to 3D bounding boxes.
Just like LLM, Cube-LLM improves its prediction by chain-of-thought prompting (CoT), connecting similar reasoning steps together from 2D to 3D bounding boxes.
Cube-LLM can further improve its predictions by incorporating specialist models of any modalities. Cube-LLM simply takes their predictions as additional prompt.
























@article{cho2024language,
title={Language-Image Models with 3D Understanding},
author={Cho, Jang Hyun and Ivanovic, Boris and Cao, Yulong and Schmerling, Edward and Wang, Yue and Weng, Xinshuo and Li, Boyi and You, Yurong and Kr{\"a}henb{\"u}hl, Philipp and Wang, Yan and others},
journal={arXiv preprint arXiv:2405.03685},
year={2024}
}